
地下偶像团体招募
地下偶像团体招募🚂✰ ゚☾~☄︎*✩‧₊ ✰˚* ੈ₊ ✰’’☄︎* ゚☾- ੈ✩‧₊✰*♫⊹以空间为纸,以时间为笔就此摆脱千篇一律的日常,将脉搏相连穷究无限浩瀚宇宙中瑰秘幻想🌠 坐标吉林长春的 王道系地下偶像团体新人招募中🎤…… 启程之时,就在此刻于空时原点呼唤旅人们的到来请成为我们中的一员吧记录悸动的手账为这个舞台留下闪耀的一笔 更多请联系QQ:781347897vx: Ksjx1234560

Ai技巧记录(Adobe illustrator)
Ai小技巧记录本文非常个人向,当作笔记记录一下小白在轻度使用时必备的一些技能,发文时刚刚进行一个Logo设计,发现很多基本操作已经忘却了,在此记录一下可以参考另一篇Ai实战记录博客 怎样画一张轨道交通图 剪切图形例如,我们需要一个不规则半圆,其实可以直接用椭圆工具画一个,然后点住顶部小圆点/在顶部选择扇形角度即可但剪切图形显然更加普适 画一个圆,点’Ctrl+Shift+O’,让图形自动识别边框路径点 使用钢笔工具在剪切位置画一道直线 打开’窗口-路径查找器-分割’ 选择取消编组 得到一个新的图形 设计字体有时候我们遇到一个很喜欢的字体,但些许设计我们不满意,可以手动调整 选中字 点’Ctrl+Shift+O’,让图形自动识别边框路径点 取消编组 使用路径点工具,调整字的形状,可以实现笔画更改、圆角,配合上文提到的路径查找器可以实现更多设计
Flutter链接MySQL
Flutter链接MySQL1. 前言Flutter官方对两种数据库更加推荐,且为它们提供了更好的支持,分别是SQLite:一种本地数据库,优点顾名思义,更加轻量化,且对移动设备的支持更好;缺点是无法云上部署并通过IP链接FireBase:由Google官方提供的NoSQL数据库,向用户提供了非常丰富的API接口,且为多用户聊天提供了很好的原生支持,是制作聊天功能的首选 这里仍然选择MySQL的原因: 没学过数据库,用老牌数据库学一下常规操作先 可以云上部署,在自己的服务器上部署特别方便 在腾讯云服务器上部署规避Google科学上网的限制 2. MySQL 安装 简单配置Ubuntu 服务器打开终端用ssh命令行安装还是太麻烦了直接用宝塔的数据库功能,点添加数据库,填写config就好更细致的操作,如创建用户、编辑权限、创建表等,点击phpMyAdmin进入php管理页面操作 Windows在MySQL官网下载安装包后安装 SQL 可视化管理工具推荐DBeaver,官网下载安装即可配置简单,界面直观,功能丰富可以管理云端数据库支持多种SQL 常用命令启动:net start...

易拉宝展示
易拉宝展示以下是个人的易拉宝作品展示(未展出易拉宝暂不上传)随缘接单欢迎扩列 QQ:1439429910 ...
GPIO学习
GPIO | 红外探测GPIO | 红外探测小车的循迹功能就是通过4路红外探测黑线来实现的 GPIO 简介GPIO就是从STM32芯片上引出的引脚,可以通过拉高/拉低电平等方式简单粗暴地控制,也可以使用TIM、UART等系统资源控制,也可以检测GPIO端口电平的高低来实现数据输入。 GPIO输出–以点亮LED为例编程顺序 使能GPIO端口时钟 初始化GPIO引脚 控制GPIO输出高、低电平 代码分析1.在.h文件中列出需要的GPIO的宏编程时使用宏定义便于提高程序的可移植性每个.h文件都include这个头文件#include "stm32f10x.h" 12345678/* 定义LED连接的GPIO端口, 用户只需要修改下面的代码即可改变控制的LED引脚 */#define LED1_GPIO_PORT GPIOC /* GPIO端口 */#define LED1_GPIO_CLK RCC_APB2Periph_GPIOC /* GPIO端口时钟 */#define...
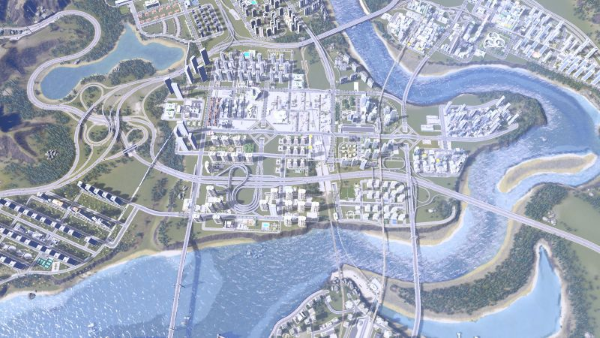
怎样画一张轨道交通图
怎样画一张地铁图 | Ai1.使用钢笔工具,点击创建锚点后,按住 shift 移动光标(shift使光标只能水平、垂直、45°移动),继续创建锚点画出线路基本走向 2.调整描边颜色、端点和转角为圆滑 3.在 fx - 风格化 - 圆角 中选择线路转弯处圆角半径 4.使用椭圆工具,按住 shift 画出正圆,作为地铁站图标 5.搭配使用多边形工具、钢笔工具、曲率工具画出不规则图标 6.添加一点创意 7.导出时选择全画布导出 附上:城市天际线架空城市轨道交通图